For any OPs team one of the goals is to deploy services with as little operational overhead as possible. This means designing infrastructure that is resilient and self-healing. Recently I had an opportunity to apply these principles to part of $EMPLOYERS core internal services; our logging stack.
The first part of the task was to identify what properties we required of this system:
- Scalable
- Being logging infrastructure this system needed to support high volumes of ingest data as well as querying data at rest.
- Highly Available
- We should be at least able to queue logs to later ingest if some part of the system isn’t working.
- Resilient storage
- Some logs, like security logs, we may need to keep for long periods of time in a secure manner.
- Low operational overhead
- Though we need this system to be available we don’t want to spent to much time keeping it running.
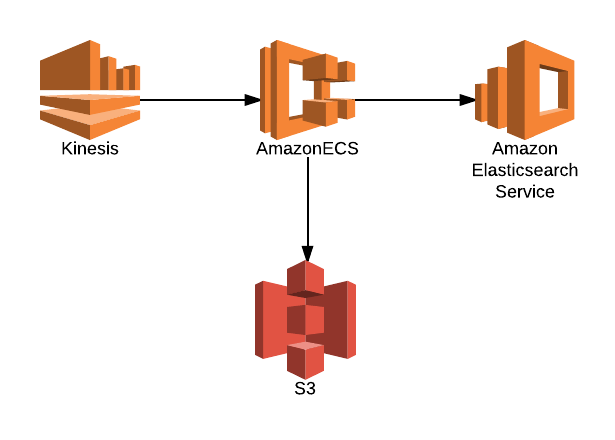
This is what we ended up with:
- Ingest
- Processing
- Storage
- Interface
- Kibana (built into the ElasticSearch Service)
This gives us all of the features we are looking for. Within reasonable limits all of these components are scalable to very large data volumes. By running ECS cluster on top of an ASG spread across AZs we have a high degree of availability for all components. S3, as we all know, has a somewhat absurd number of 9s around data durability and we can leverage versioning, access logs as well as encryption at rest to ensure data integrity. Kinesis was the newest piece to me, highly scalable and fast, I think it will be core to similar infrastructures for me in the future.
All of this was of course rolled up into a reusable Terraform module. This allows our team to roll this out for different environments in a reproducible manner.